SenseCheck: AI-Powered Comms Stress-Testing
Designed and built a demographic simulation platform that lets organisations stress-test draft announcements against 148,000 synthetic Singapore personas before publication. SenseCheck identifies which phrases trigger negative reactions in which segments, and recommending targeted rewrites with validated improvement.
Task
Conceptualized, designed, and developed a comprehensive banking calculator tool that enables users to compare interest rates and potential returns from different banks, considering multiple qualification criteria.
Government agencies and large organisations draft policy announcements without knowing how specific resident segments will react until after publication. A single dismissive phrase can dominate public discourse for weeks. By the time you know it’s a problem, the damage is done.
The traditional alternatives are surveys and focus groups. They’re slow (weeks to months), expensive, and biased toward respondents who self-select — meaning the voices most affected by a policy change are often the least represented.
Existing synthetic persona tools (notably NVIDIA’s Nemotron-Personas-Singapore demos) had shown that AI-driven simulation could produce demographically differentiated sentiment. But these were one-shot explorations. None offered the thing a communications officer actually needs: which specific phrases are the problem, for which specific segments, and what should I change them to — with proof that the change actually helps.
That was the gap SenseCheck was designed to close: an iterative testing pipeline that goes from diagnosis to validated fix in minutes.
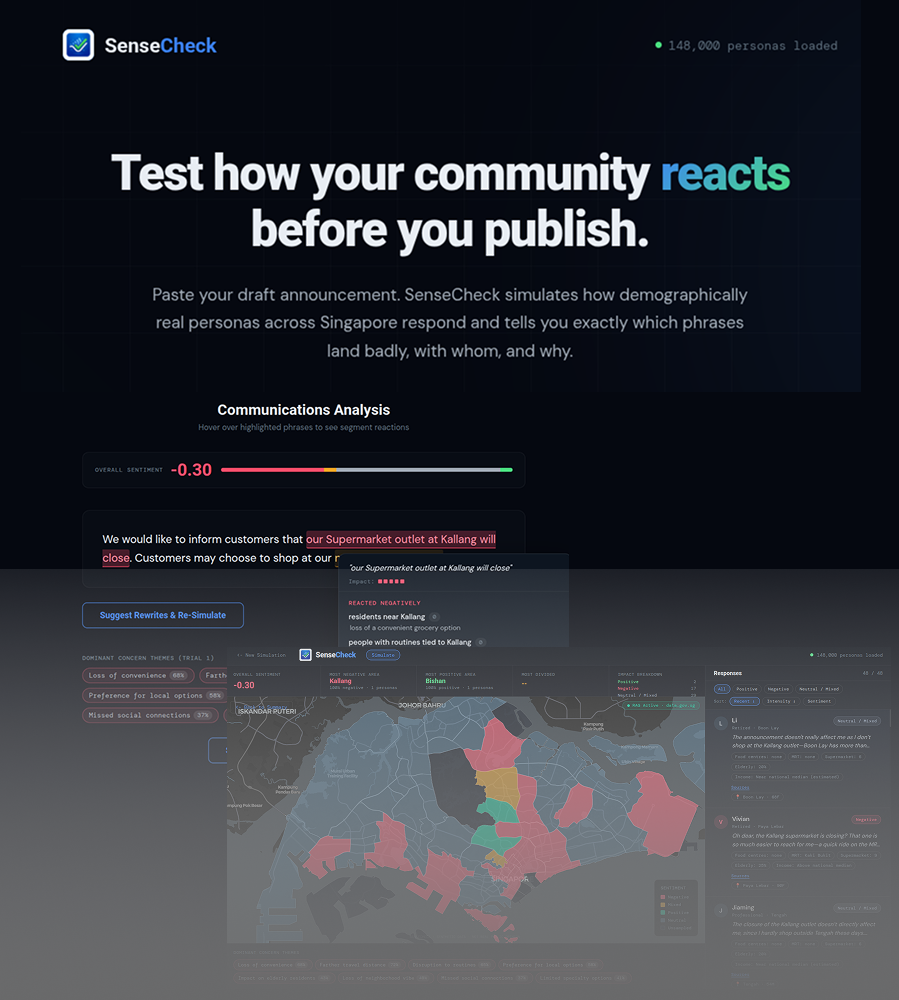
The simplest useful version. A communications officer pastes their draft announcement. The system samples 50 personas from a dataset of 148,000 synthetic Singaporeans (NVIDIA Nemotron-Personas-Singapore, CC BY 4.0), using population-weighted stratified sampling so the persona mix reflects Singapore’s actual demographic distribution per planning area. Each persona is run through Claude Sonnet with role-based prompting and returns structured output: sentiment direction, intensity score, trigger phrase, and reasoning.
The results render on a choropleth map of Singapore’s planning areas, colour-coded by dominant sentiment. A persona feed sidebar shows each individual reaction with sentiment badges and the exact phrase that drove it.
Architecture: Draft Announcement → Persona Sampler (stratified by planning area) → Claude Sonnet (role-based prompt, zero-shot) → Structured Output (SENTIMENT / INTENSITY / TRIGGER_PHRASE / REASONING) → Choropleth Map + Persona Feed + Phrase Attribution
Design decisions that mattered:
Parallel API calls with a batch size of 48, targeting 50 personas simulated in under 15 seconds. Claude Sonnet was chosen for persona reasoning — best instruction-following for role-based simulation — while MiniMax and GPT-4o-mini handle cheaper sub-tasks like theme extraction and concern tagging at 3–4x lower cost.
What worked:
The phrase-level attribution was immediately useful. In a test scenario with a hawker centre closure announcement for Toa Payoh, 72% of elderly low-income personas reacted negatively with an average intensity of -3.8. The phrase “explore nearby dining options” was flagged as the top trigger — personas interpreted it as dismissive of their daily food access needs. That level of specificity — not just “elderly people are unhappy” but “this phrase is the reason” — was the core value proposition validated.
What the evaluation revealed was missing:
When I compared responses across planning areas, a Toa Payoh elderly persona sounded nearly identical to a Punggol elderly persona. They were reacting to the same phrases with the same reasoning, just with different names. The grounding delta eval — comparing whether responses were actually differentiated by location — failed. Without real local context, every persona was reasoning from the same generic understanding of Singapore.
That signal triggered Iteration 2.
RAG: Making Personas Sound Like They Live Where They Live
Before each persona call, the system now retrieves real hyperlocal data from data.gov.sg by planning area: nearby hawker centres, MRT stations, supermarkets, parks, median household income, age distribution, and flat type mix. This is injected as a LOCAL ENVIRONMENT block in the system prompt, so each persona responds with awareness of their actual neighbourhood.
A deliberate retrieval decision: this is a direct JSON lookup by planning area, not semantic search. Planning area demographics are structured tabular data — income bands, amenity counts, flat type distributions. Embeddings can’t capture the semantics of exact values. A direct lookup is faster, cheaper, and more accurate. This was informed by the principle that semantic retrieval struggles on tabular data where precision matters.
A cost optimisation followed naturally: the demographic block is identical for all personas in the same planning area, so it’s placed at the top of the prompt as a cacheable prefix. Repeated calls for Toa Payoh personas reuse the cached context, reducing cost by roughly 90% for same-area batches.
The grounding delta was immediately visible. A Toa Payoh elderly persona now references actual hawker centres and real walking distances to alternatives. A Punggol young family persona references Waterway Point food court. The responses became location-specific rather than generic. The eval that had failed in Iteration 1 now passed.
Unlike typical calculators that simply present data, I took an analytics-first design approach focused on transforming raw calculations into actionable insights. This included creating a logical flow from input variables to insight presentation, developing progressive disclosure hierarchy for complex information, and designing a comparative visualization framework highlighting key differences.
The technical architecture was designed to support complex calculations while maintaining performance and scalability:
- Modular Calculation Engine: Separated core calculation logic from presentation layer
- Data Management: Used Supabase for structured storage of rates and criteria
- Performance Optimization: Implemented calculation memoization to improve response time
- Analytics Implementation: Designed event tracking for feature usage patterns
I established a comprehensive measurement framework to evaluate product success, focusing on these primary metrics:
- User Confidence Score: Measured through post-calculation survey
- Decision Time: Time from initial visit to completion of comparison
- Optimization Value: Percentage improvement through fund distribution optimization
- Satisfaction Rating: Post-usage satisfaction survey results
I implemented a robust analytics architecture to measure both usage and impact, with an event tracking framework aligned with the user journey, a feedback collection system, and performance monitoring for calculation response time.
Early results demonstrate significant impact on user financial decision-making:
- 76% of users report increased confidence in their banking decisions
- Average optimization value of 21% through the fund distribution algorithm
- Decision time reduced by 89% compared to manual comparison methods
- 4.7/5 average satisfaction rating from post-usage surveys
User feedback revealed several key insights: transparency drives trust, with users particularly valuing understanding exactly how interest is calculated; the fund distribution optimization feature receives the highest satisfaction ratings; and mobile usage exceeds expectations, with 68% of users accessing the tool via mobile devices and spending 24% more time exploring different scenarios.
SmartSaver has evolved significantly from its initial concept, with each release adding valuable functionality based on user feedback and strategic priorities: