Topic Modelling of Song Lyrics to Predict Billboard Longevity
Developed a machine learning pipeline that fuses Natural Language Processing (NLP) with audio feature analysis to quantify the impact of lyrical themes on commercial music success.
Task
End-to-end data science lifecycle: from scraping and cleaning complex text data to building and evaluating predictive models (Random Forest, Gradient Boosting) to forecast song popularity

In the music industry, chart longevity is the ultimate proxy for revenue and cultural relevance. While traditional analytics focus heavily on audio features (tempo, key, beat), the lyrical content—the actual story the song tells—is often treated as unstructured, qualitative noise.
I set out to challenge this by building a predictive pipeline that fuses Natural Language Processing (NLP) with audio feature analysis. My objective was to answer two specific questions:
-
Can we mathematically model the “topic” of a song without human labeling?
-
Does the theme of a song (e.g., “Love” vs. “Introspection”) statistically correlate with how long it survives on the Billboard Hot 100?
Data Engineering Pipeline
To build a representative dataset, I orchestrated a multi-source ingestion pipeline covering 3,602 unique songs4.
- Target Variable: Historical Billboard Hot 100 data (weeks on chart) sourced from Kaggle5
-
Audio Features: Extracted granular acoustic metadata (Danceability, Energy, Valence) via the Spotify API6.
-
Text Data: Scraped raw lyrics for every track using the Genius API7.
The NLP Challenge: Cleaning “Messy” Creative Text
Song lyrics are unstructured and notoriously difficult to normalize. I implemented a rigorous preprocessing workflow to prepare the corpus for modeling8:
-
Sanitization: Removed structural markers (e.g.,
[VERSE],[CHORUS]) and non-standard characters to flatten the text9. -
Dimensionality Reduction: Filtered out tokens appearing in >80% of songs (to remove generic pop tropes) and tokens shorter than 3 characters10101010.
-
Normalization: Applied Lemmatization to reduce words to their root forms (e.g., “running” -> “run”) and removed stop words/profanities to isolate thematic meaning1
Feature Extraction: Topic Modelling (LDA)
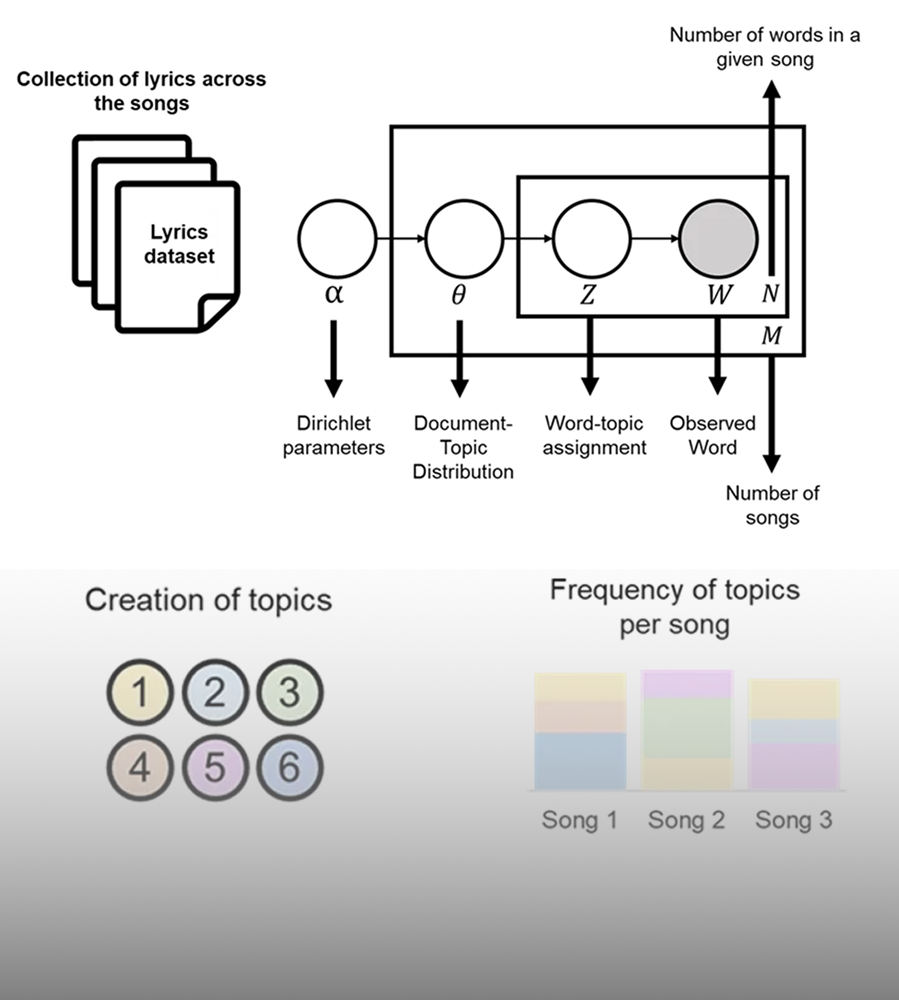
Instead of simple sentiment analysis, I used Latent Dirichlet Allocation (LDA) to discover hidden thematic structures within the lyrics12.
To determine the optimal number of topics ($k$), I trained multiple models ($k=5$ to $15$) and evaluated them using Coherence Scores. The model peaked at 10 topics, maximizing semantic distinctiveness13.
The “Vibe” Quantified: The LDA model successfully clustered songs into human-interpretable categories. Analyzing the descriptive statistics revealed a fascinating trend:
Insight: Songs about “Inner Feelings & Metaphysical” concepts averaged 21.3 weeks on the charts, whereas “Spirituality & Conflict” songs averaged only 13.5 weeks.
Predictive Modeling: Regression Benchmarking
I treated chart longevity as a continuous regression problem. I benchmarked five algorithms, utilizing K-Fold Cross-Validation to ensure the results weren’t skewed by random data splits15.
Model Results (Metric: $R^2$ Score)
- Random Forest: 0.9657 (Winner) 16
- Gradient Boosting: 0.9573 17
- Neural Network: 0.9495 18
- Linear Regression: 0.8506 19
The massive performance gap between Linear Regression and Random Forest highlights that the drivers of pop music success are highly non-linear20.
While the Random Forest model achieved high accuracy, a Feature Importance analysis revealed a nuanced reality:
-
Audio is King: Acoustic features (like danceability and instrumentalness) remained the primary predictors of longevity.
-
Lyrics are Secondary: The LDA topics had low feature importance scores compared to audio metadata.
-
The “Sad Banger” Paradox: Despite low overall predictive weight, specific topics like “Life Reflections” were the most influential among the lyrical features, suggesting that while the beat hooks the listener, the meaning might help retain them
What I would do differently: The dataset suffered from survivorship bias, as it only included songs that had already charted. A more robust version of this model would include a “negative class” of songs that were released but never charted, allowing the model to predict “hit potential” rather than just “hit duration”.
Business Value: This project demonstrates that we can effectively structure unstructured creative data. For a record label, this pipeline could be adapted to tag vast demos automatically or identify lyrical trends in emerging sub-genres before they hit the mainstream.